Why Local-First Software Is the Future and what are its Limitations
Imagine a web app that behaves seamlessly even with zero internet access, provides sub-millisecond response times, and keeps most of the user's data on their device. This is the local-first or offline-first approach. Although it has been around for a while, local-first has recently become more practical because of maturing browser storage APIs and new frameworks that simplify data synchronization. By allowing data to live on the client and only syncing with a server or other peers when needed, local-first apps can deliver a user experience that is fast, resilient, and privacy-friendly.
However, local-first is no silver bullet. It introduces tricky distributed-data challenges like conflict resolution and schema migrations on client devices. In this article, we'll dive deep into what local-first means, why it's trending, its pros and cons, and how to implement it in real applications. We'll also discuss other tools, criticisms, backend considerations, and how local-first compares to traditional cloud-centric approaches.
What is the Local-First Paradigm
In local-first software, the primary copy of your data lives on the client rather than a remote server. Rather than sending each read or write over the network, you store and manipulate data in a local database on the user’s device. Sync then happens in the background, ensuring all devices eventually converge to a consistent state.
This approach is increasingly popular because it leads to instant app responses (no network delay for most operations), genuine offline capability, and more direct data ownership for users. Local-first apps also sidestep outages and if the server or internet goes down, users can keep working with their local data. When connectivity returns, everything syncs. This makes the user experience more resilient and gives them control of their data, which is especially appealing when privacy concerns or limited connectivity are key factors.
Local-First software: A set of principles for software that enables both collaboration and ownership for users. Local-first ideals include the ability to work offline and collaborate across multiple devices, while also improving the security, privacy, long-term preservation, and user control of data.
- Ink & Switch, 2019
Why Local-First is Gaining Traction
The push for local-first is driven by a few key new technological capabilities that previously restricted client devices from running heavy local-first computing:
-
Relaxed Browser Storage Limits: In the past, true local-first web apps were not very feasible due to storage limitations in browsers. Early web storage options like cookies or localStorage had tiny limits (~5-10MB) and were unsuitable for complex data. Even IndexedDB, the structured client storage introduced over a decade ago, had restrictive quotas on many browsers: For example, older Firefox versions would prompt the user if more than 50MB was being stored. Mobile browsers often capped IndexedDB to 5MB without user permission. Such limits made it impractical to cache large application datasets on the client. However, modern browsers have dramatically increased these limits. Today, IndexedDB can typically store hundreds of megabytes to multiple gigabytes of data, depending on device capacity. Chrome allows up to ~80% of free disk space per origin (tens of GB on a desktop), Firefox now supports on the order of gigabytes per site (10% of disk size), and even Safari (historically strict) permits around 1GB per origin on iOS. In short, the storage quotas of 5-50MB are a thing of the past and modern web apps can cache very large datasets locally without hitting a ceiling. This shift in storage capabilities has unlocked new possibilities for local-first web apps that simply weren't viable a few years ago.
-
New Storage APIs (OPFS): The new Browser API Origin Private File System (OPFS), part of the File System Access API, enables near-native file I/O from within a browser. It allows web apps to manage file handles securely and perform fast, synchronous reads/writes in Web Workers. This is a huge deal for local-first computing because it makes it feasible to embed robust database engines directly in the browser, persisting data to real files on a virtual filesystem. With OPFS, you can avoid some of the performance overhead that comes with IndexedDB-based workarounds, providing a near-native speed experience for file-structured data.

- Bandwidth Has Grown, But Latency Is Capped: Internet infrastructure has rapidly expanded to provide higher throughput making it possible to transfer large amounts of data more quickly. However, latency (i.e., round-trip delay) is constrained by the speed of light and other physical limitations in fiber, satellite links, and routing. We can always build out bigger "pipes" to stream or send bulk data, but we can't significantly reduce the base round-trip time for each request. This is a physical limit, not a technological one. Local-first strategies mitigate this fundamental latency limit by avoiding excessive client-server calls in interactive workflows, once data is on the client, it's instantly available for reads and writes without waiting on a network round-trip. Imagine, transferring around 100,000 "average" JSON documents might only consume about the same bandwidth as two frames of a 4K YouTube video which can be transferred in milliseconds. This shows just how far raw data throughput has come. Yet each request still has a 100-200ms latency or more, which becomes noticeable in user interactions. Local-first mitigates this by minimizing round-trip calls during active use and using the available bandwidth to directly transfer most of the data on the first app start.
-
WebAssembly: Another advancement is WebAssembly (WASM), which allows developers to compile low-level languages (C, C++, Rust) for execution in the browser at near-native speed. This means database engines, search algorithms, vector databases, and other performance-heavy tasks can run right on the client. However, a key limitation is that WASM cannot directly access persistent storage APIs in the browser. Instead, all data must be sent from WASM to JavaScript (or the main thread) and then go through something like IndexedDB or OPFS. This extra indirection is slower compared to plain JavaScript->storage calls. Looking ahead, there might come up future APIs that allow WASM to interface with persistent storage directly, and if those land, local-first systems could see another major boost in performance.
-
Improvements in Local-First Tooling: A major factor fueling the rise of local-first architectures is the dramatic leap in client-side tooling and performance. For instance, consider a local-first email client that stores one million messages. In 2014, searching through that many documents, especially with something like early PouchDB, could take minutes in a browser. Today, with advanced offline databases like RxDB, you can use the OPFS storage with sharding across multiple web workers (one per CPU) and use memory-mapped techniques. The result is a regex search of one million of these email documents in around 120 milliseconds - all in JavaScript, running inside a standard web browser, on a mobile phone.
Better yet, this performance ceiling is likely to keep rising. Newer browser features and WebAssembly optimizations could enable even faster indexing and query operations, closing the gap with native desktop clients. I even experimented with GPU-accelarated queries (using WebGPU) which, while still in experimental stage, might deliver client-side performance that outperforms servers which do not have a graphics card. These transformations highlight why local-first has become truly practical: not only can you sync and work offline, but you can handle serious data loads with performance that would have been unthinkable just a few years ago.
What you can expect from a Local First App
Jevons' Paradox says that making a resource cheaper or more efficient to use often leads to greater overall consumption. Originally about coal, it applies to the local-first paradigm in a way where we require apps to have more features, simply because it is technically possible, the app users and developers start to expect them:
User Experience Benefits

- Performance & UX: Running from local storage means low latency and instantaneous interactions. There's no round-trip delay for most operations. Local-first apps aim to provide near-zero latency responses by querying a local database instead of waiting for a server response. This results in a snappy UX (often no need for loading spinners) because data reads/writes happen immediately on-device. Modern users expect real-time feedback, and local-first delivers that by default.
- User Control & Privacy: Storing data locally can limit how much sensitive information is sent off to remote servers. End users have greater control over their data, and the app can implement client-side encryption, thereby reducing the risk of mass data breaches. Its even possible to only replicated encrypted data with a server so that the backend does not know about the data at all and just acts as a backup/replication endpoint.

- Offline Resilience: Obviously, being able to work offline is a major benefit. Users can continue using the app with no internet (or flaky connectivity), and their changes sync up once online. This is increasingly important not just for remote areas, but for any app that needs to be available 24/7. Even though mobile networks have improved, connectivity can still drop; local-first ensures the app doesn't grind to a halt. The app "stores data locally at the client so that it can still access it when the internet goes away."
-
Realtime Apps: Today's users expect data to stay in sync across browser tabs and devices without constant page reloads. In a typical cloud app, if you want real-time updates (say to show that a friend edited a document), you'd need to implement a websocket or polling system for the server to push changes to clients, which is complex. Local-first architectures naturally lend themselves to realtime-by-default updates because the application state lives in a local database that can be observed for changes. Any edits (local or incoming from the server) immediately trigger UI updates. Similarly, background sync mechanisms ensure that new server-side data flows into the local store and into the user interface right away, no need to hit F5 to fetch the latest changes like on a traditional webpage.
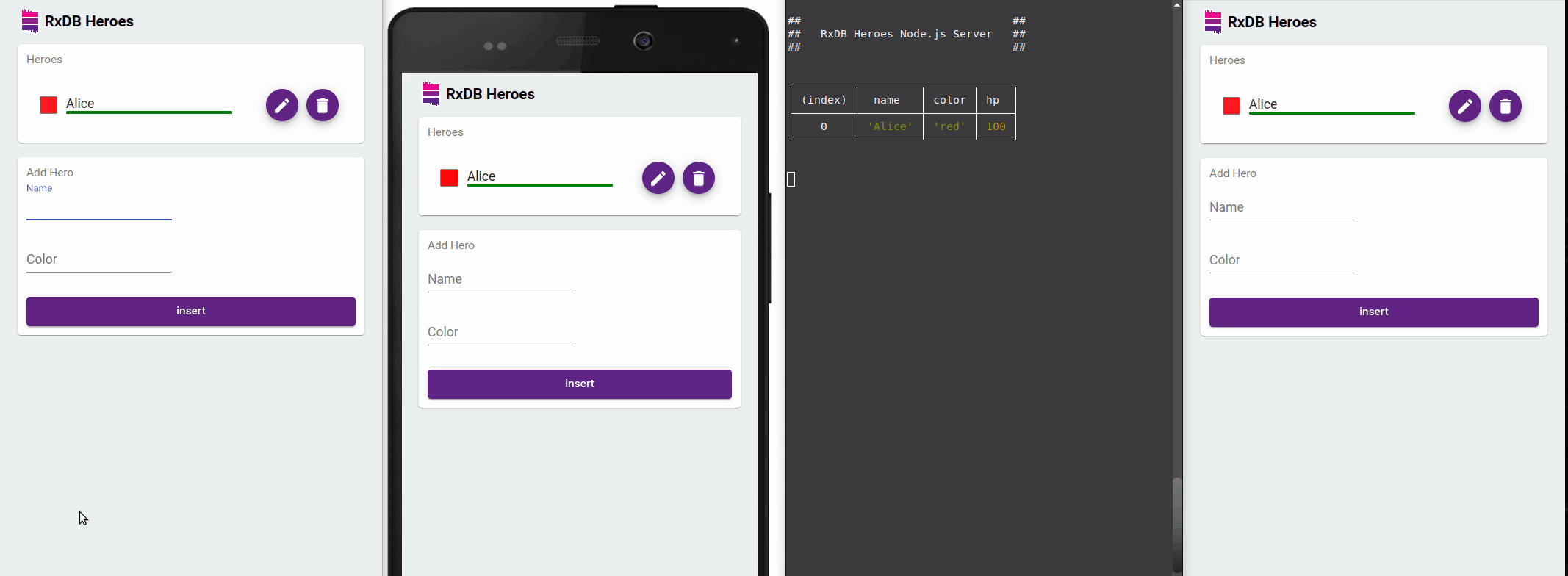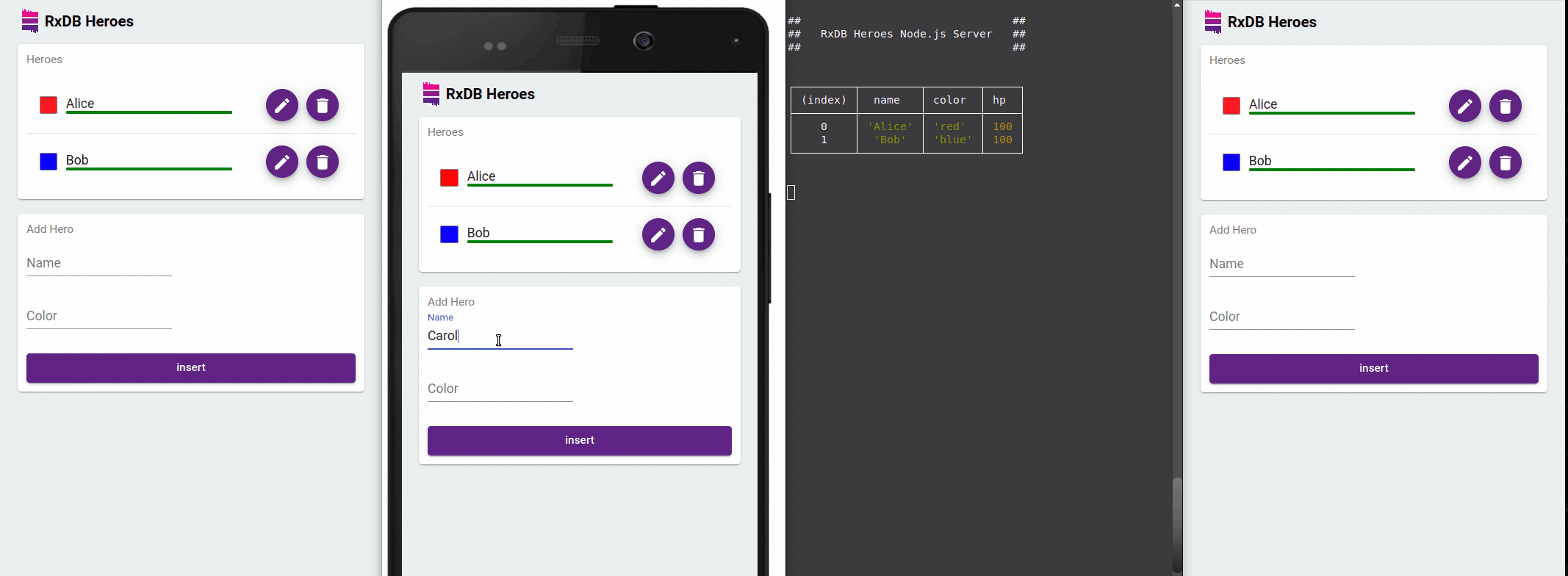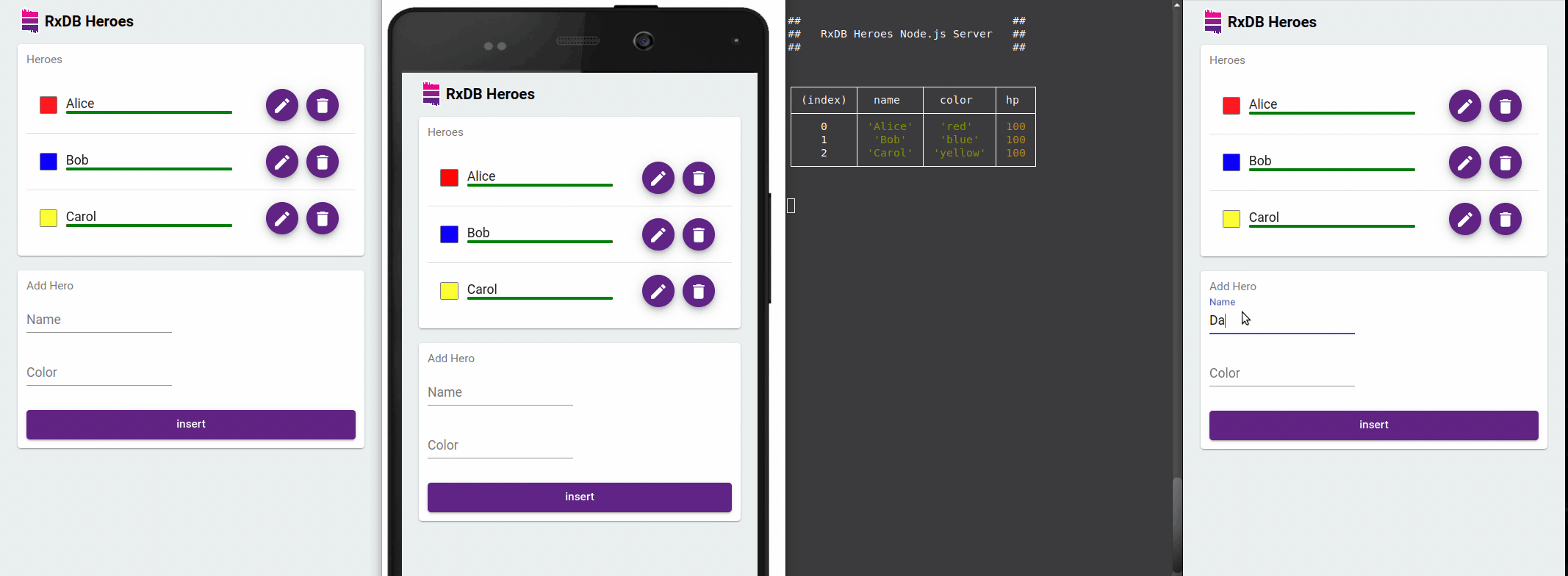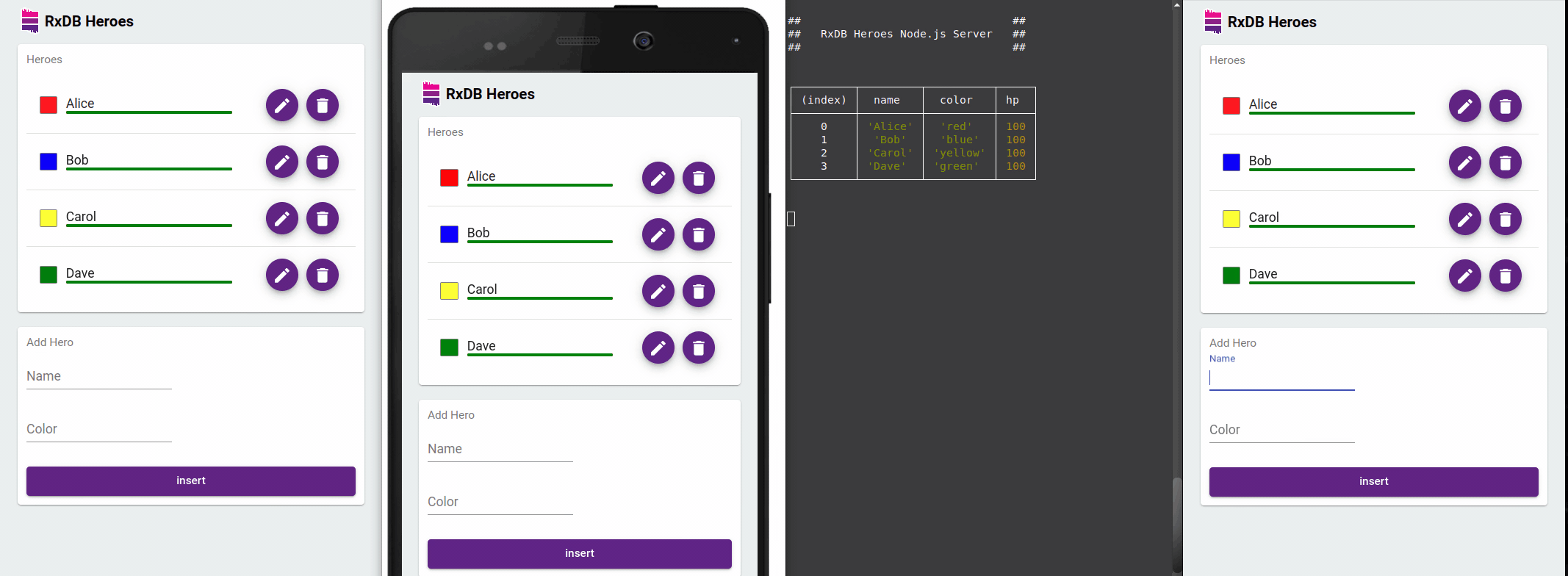
Developer Experience Benefits
-
Reduced Server Load: Because local-first architectures typically transfer large chunks of data once (e.g., during an initial sync) and then sync only small diffs (delta changes) afterward, the server does not have to handle repeated requests for the same dataset. This bulk-first, diff-later approach drastically decreases the total number of round-trip requests to the backend. In scenarios where hundreds of simultaneous users each require continuous data access, an offline-ready client that only periodically sends or receives changes can scale more efficiently, freeing your servers to handle more users or other tasks. Instead of being bombarded with frequent small queries and updates, the server focuses on periodic sync operations, which can be more easily optimized or batched. It Scales with Data, Not Load. In fact for most type of apps, most of the data itself rarely changes. Imagine a CRM system. How often does the data of a customer really change compared to how often a user opens the customer-overview page which would load data from a server in traditional systems?
-
Less Need for Custom API Endpoints: A local-first architecture often simplifies backend design. Instead of writing extensive REST routes for each client operation (create, read, update, delete, etc.), you can build a single replication endpoint or a small set of endpoints to handle data synchronization for each entity. The client manages local data, merges edits, and pushes/pulls changes with the server automatically. This not only reduces boilerplate code on the backend but also frees developers to focus on business logic and domain-specific concerns rather than spending time creating and maintaining dozens of narrowly scoped endpoints. As a result, the overall system can be easier to scale and maintain, delivering a smoother developer experience.
-
Simplified State Management in Frontend: Because the local database holds the authoritative state, you might rely less on complex state management libraries (Redux, MobX, etc.). The DB becomes a single source of truth for your UI. In an offline-first app, your global state is already there in a single place stored inside of the local database, so you don't need as many in-memory state layers to synchronize. The UI can directly bind to the database (using queries or reactive subscriptions). All sources of changes (user input, remote updates, other tabs) funnel through the database. This can significantly reduce the "glue code" to keep UI state in sync with server state because the local DB does that for you. With Local-First tools, "you might not need Redux" because the reactive DB fulfills that role of state management already.
-
Observable Queries: One of the big advantages of storing data locally is the ability to subscribe to data changes in real time, often called observable queries. When the data changes - either from the user's actions or from a remote sync - the local database automatically updates the subscribed query results, and the UI can redraw without a manual refresh. This reactive pattern can make apps feel much more live and responsive.
In the beginnings this was mostly done by watching a changes feed (like in PouchDB) and re-running queries whenever data changed. However, this early approach was slow and didn't scale well, because the entire query had to be recalculated each time. Later, RxDB introduced the EventReduce Algorithm, which merges incoming document changes into an existing query result by using a big binary decision tree. With this, updated query results can be "calculated" on the CPU instead of re-running them over the database. This makes query updates almost instantaneous and scales better as your data grows. Nowadays, many local databases have added similar features: for example, dexie.js introduced
liveQuery, letting developers build real-time UIs without repeatedly scanning the entire dataset. -
Better Multi-Tab and Multi-Device Consistency: Because the source of truth is on the client, if the user has the app open in multiple tabs or even multiple devices, each has a full copy of the data. In browsers, many offline databases use a storage like IndexedDB that is shared across tabs of the same origin. This means all tabs see the same up-to-date local state. For example, if a user logs in or adds data in one tab, the other tab can automatically reflect that change via the shared local DB and events. This solves a common issue in web apps where one tab doesn't know that something changed in another tab. With local-first, multi-tab just works by default because there's "exactly one state of the data across all tabs". Similarly, on multiple devices, once sync runs, each device eventually converges to the same state.
If your users have to press F5 all the time, your app is broken!
-
Potential for P2P and Decentralization: While most current local-first apps still use a central backend for syncing, the paradigm opens the door to peer-to-peer data syncing. Because each device has the full data, devices could sync directly via LAN or other P2P channels for collaboration, reducing reliance on central servers. There are experimental frameworks that allow truly decentralized sync. This is a more advanced benefit, but it aligns with the ethos of giving users more control and reducing dependence on any one cloud provider.
These advantages show why developers are excited about local-first. You get happier users thanks to a fast, offline-capable app, and you can differentiate your product by working in scenarios where others fail (e.g. poor connectivity). Companies like Google, Amazon, etc., invest heavily in reducing latency and adding offline modes for a reason: it improves retention and usability. Local-first design takes that to the extreme by default.
Challenges and Limitations of Local-First
However, this approach is not without significant challenges. It's important to understand the drawbacks and trade-offs before deciding to go all-in on local-first. Let's examine the flip side.
Critics of local-first approaches often point out these challenges. Here's a comprehensive list of cons, criticisms, and obstacles associated with local-first development and proposed solutions on how to solve these obstacles:
- Data Synchronization: Data synchronization is arguably the hardest part of local-first development, because when every user's device can be offline for extended periods, data inevitably diverges. Ensuring those changes propagate and reconcile with minimal user headaches is a major challenge in distributed systems. Two main approaches have emerged:
-
Use a bundled frontend+backend solution where the backend is tightly coupled to the client SDK and knows exactly how to handle sync. A common example is Firestore (part of the Firebase ecosystem) where Google's servers and client libraries collectively manage storage, change detection, conflict resolution, and syncing. The upside is you have a turnkey solution, developers can focus on features rather than writing sync logic. The downside is lock-in, because the sync protocol is proprietary and tailored to that vendor. In many organizations, this is a non-starter: existing company infrastructure can't be uprooted or replaced just for a single offline-capable app. This lock-in issue can arise even if the backend is not strictly a third-party vendor but simply another technology like PostgreSQL, because it still forces you to consolidate all your data into a single system that you might not use otherwise.
-
Custom Replication with Your Own Endpoints: Alternatively, tools like RxDB allow you to implement your own replication endpoints on top of your existing infrastructure. This is the approach relies on a lightweight, git-like Sync Engine. The server remains relatively "dumb," focusing on storing revisions, tracking changes, and marking conflicts, while the client library does the actual conflict resolution. During sync, if the server detects a conflict (e.g., two offline edits to the same document), it notifies the client, which then decides how to merge them, whether via last-write-wins, a custom merge function, or a CRDT. Setting up custom endpoints does require more development effort, but you avoid vendor lock-in and can integrate seamlessly with your existing database(s). Your system simply needs to support incrementally fetching changes (pull) and accepting local modifications (push), which can be layered on top of nearly any data store or architecture.
Tools which support "any backend" are of course harder to monetize because they cannot sell SaaS services or a Cloud Subscription which is why most tools use a fixed backend instead of an open Sync Engine.
-

-
Conflict Resolution: When multiple offline edits happen on the same data, you inevitably get merge conflicts. For example, if two users (or the same user on two devices) both edit the same document offline, when both sync, whose changes win? Local-first systems need a conflict resolution strategy. Some systems use last-write-wins (firestore) or deterministic revision hashing to pick a "winner" (as in CouchDB/PouchDB). This is simple but may drop one user's changes. Other approaches keep both versions and merge them either via an implement "merge-function" or require a manual merge step (e.g., like git conflicts or showing the user a diff UI). More advanced solutions involve CRDTs (Conflict-free Replicated Data Types) which mathematically merge changes (used for rich text collaboration, for instance). Libraries like Automerge or Yjs implement CRDTs to "magically solve conflicts". But in practice, using CRDTs is also complex and has its own trade-offs and sometimes not even possible like when you need additional data from another instance for a "correct" merge. No matter which route, handling conflicts adds complexity to your app logic or infrastructure. In cloud-based (online-first) apps, you avoid this because everyone is always editing the single up-to-date copy on the server. Local-first shifts that burden to the client side.
Here is an example on how a client-side merge functions works in RxDB:
import { deepEqual } from 'rxdb/plugins/utils'; export const myConflictHandler = { /** * isEqual() is used to detect if two documents are * equal. This is used internally to detect conflicts. */ isEqual(a, b) { /** * isEqual() is used to detect conflicts or to detect if a * document has to be pushed to the remote. * If the documents are deep equal, * we have no conflict. * Because deepEqual is CPU expensive, * on your custom conflict handler you might only * check some properties, like the updatedAt time or revision-strings * for better performance. */ return deepEqual(a, b); }, /** * resolve() a conflict. This can be async so * you could even show an UI element to let your user * resolve the conflict manually. */ async resolve(i) { /** * In this example we drop the local state and use the server-state. * This basically implements a "first-on-server-wins" strategy. * * In your custom conflict handler you could want to merge properties * of the i.realMasterState, i.assumedMasterState and i.newDocumentState * or return i.newDocumentState to have a "last-write-wins" strategy. */ return i.realMasterState; } };
-
Eventual Consistency (No Single Source of Truth): A local-first system is eventually consistent by nature. There is no single authoritative copy of the data at all times. Instead you have one per device (and maybe one on the server), and they sync to become consistent eventually. This means at any given moment, two users might not see the same data if one hasn't synced recently. Users could even make decisions based on stale data. In many applications this is acceptable (the data will catch up), but for some scenarios it's problematic. For instance, an offline-first banking app that lets you initiate a money transfer offline could be dangerous if the account balance was out-of-date or if the transfer needs immediate consistency. Essentially, not all apps can tolerate eventual consistency. If your use case demands strong consistency (e.g., inventory systems where overselling is a big issue, or real-time collaborative editing where every keystroke must be seen by others instantly), a purely local-first approach might need augmentation or may not fit.
-
Initial Data Load and Data Size Limits: Local-first requires pulling data down to the client. If your dataset is huge (gigabytes), it's simply not feasible to download everything to every client. For example, syncing every tweet on Twitter to every user's phone is impossible. Local-first works best when the data set per user is reasonably sized (up to 2 Gigabytes). In practice, you often limit the data to just that user's own data or a subset relevant to them. Even then, on first use the app might need to download a significant chunk of data to initialize the local database. There is a upper bound on dataset size beyond which the initial sync or storage needs become impractical. You cannot assume unlimited local storage. If your data is too large, local-first will either fail or you'll need to only sync partial data (and then handle what happens if the needed data isn't present locally). In short, local-first is unsuitable for massive datasets or data that cannot be partitioned per user.

- Storage Persistence (Browser Limitations): Storing data in the browser (via IndexedDB or similar) is not as durable as on a server disk. Browsers may evict data to save space (especially on mobile devices). For instance, Safari notoriously wipes out IndexedDB data if the user hasn't used the site in ~7 days. Other browsers have their own eviction policies for offline data. Also, users can at any time clear their browser storage (intentionally or via something like "Clear site data"). This means the local data cannot be 100% trusted to stay forever. A well-behaved local-first app needs to be able to recover if local data is lost, usually by pulling from the server again. Essentially, the server still often serves as a backup. But if your app had any purely local data (not intended to sync), that's at risk. Mobile apps (with SQLite or filesystem storage) are a bit more stable than web browsers, but even there, uninstalls or certain OS actions can remove local data. This is a challenge: How to cache data offline for speed while ensuring if it's wiped, the user doesn't lose everything important. Cloud-only apps by contrast keep data in the cloud so it's typically safe unless the server fails (and servers are easier to backup reliably).
-
Complex Client-Side Logic & Increased App Size: A local-first app tends to be more complex on the client side. You're essentially putting what used to be server responsibilities (storage, query engine, sync logic) into the frontend. This can increase the size of your frontend bundle (including a database library, possibly CRDT or sync code, etc.). It also increases memory and CPU usage on the client, as the browser/phone is doing more work. Low-end devices or older phones might struggle if the app is not optimized. Developers need to consider performance tuning for the local database (indexing, query efficiency) just like they would on a server. So while the user gains benefits, the app developer has to manage this complexity.
-
Performance Constraints in JavaScript: Even though devices are fast, a local JS database is generally slower than a server DB on robust hardware. There are many layers (JS -> IndexedDB -> possibly SQLite under the hood) that add overhead. For example, inserting a record might go through the DB library, the storage engine, the browser's implementation, down to disk. For most UI uses this is fine (you don't need 10k writes/sec in a to-do app, you need maybe a few writes per second at most). But if your app does heavy data processing, the browser might become a bottleneck.
The key question is "Is it fast enough?". Often the answer is yes for typical usage, but developers must be mindful of not doing something on the client that truly requires big iron servers. For instance, full-text indexing of a million documents might be too slow in a client-side DB. Unpredictable performance is also a factor: Different users have different devices. A query that takes 50ms on a high-end desktop might take 500ms on a low-end phone in battery saving mode. So performance tuning and testing across devices is needed, and some heavy tasks might still belong on the server side. For example if you build a local vector database you might want to create the embeddings on the server and sync them instead of creating them on the client.
-
Client Database Migrations: As your app evolves, you'll change data models or add new fields. In a cloud-first app, you'd typically run a migration on the server database. In a local-first app, you have not only the server DB (if any) but also every client's local database to consider. Upgrading the schema means you need to write migration logic that runs on each client, perhaps the next time they launch the app after an update. Clients may be offline or not upgrade the app immediately, so you could have different versions of the schema in the wild. This complicates data handling (the sync protocol might need to handle multiple schema versions until everyone is updated). Providing a smooth migration path for local data is doable (many libraries provide migration facilities), but it requires careful testing. In a worst case, a failed migration on a client could brick the app for that user or force a full resync. This is a much bigger headache than just migrating a centralized DB at midnight while your service is in maintenance mode. 🌃
-
Security and Access Control: In cloud-based apps, enforcing data security (who can see what) is done on the server. The client only gets the data it's authorized to get. In a local-first scenario, you often need to partition data per user on the backend as well, to ensure users only sync down their own data (or data they have permission for). One simple strategy is to give each user their own database or dataset on the server and only replicate that. For example, CouchDB allows creating one database per user and replication can be scoped to that DB which makes permission handling easy. But if you ever need to query across users (say an admin view or aggregate analytics), having data split into many small DBs becomes a pain. The alternative is a single backend database with a fine-grained access control, and the client asks to sync only certain documents/fields. That usually means writing a custom sync server or using something like GraphQL with resolvers that respect permissions. In short, implementing auth and permissions in sync adds complexity. Also, any data stored on the client is theoretically vulnerable to extraction (if someone compromises the device or uses dev tools). You can encrypt local databases to prevent extraction after the server "revokes" the decryption password to mitigate the data extraction risk.

-
Relational Data and Complex Queries: Most client-side/offline databases are NoSQL/document oriented for flexibility in syncing and easy conflict handling. They may not support complex join queries or ACID transactions across multiple tables like a full SQL database would. This is partly because replicating a full relational model is much harder (maintaining referential integrity, etc., when data is partial on a client) or not even logically possible. For example if you have two offline clients running a complex
UPDATE X WHERE Y FROM Z INNER JOIN Alice INNER JOIN Bobquery and then they go online, you have no easy way of handling these conflicts.If your app has heavy relational data requirements or relies on complex server-side queries (aggregations, multi-join reports), you might find the local database either cannot do it or is too slow to do it client-side. The lack of robust relational querying is something to plan for and you might need to adjust your data model to be more document-oriented or use client-side libraries to run joins in memory. Most tools use NoSQL because it makes replication easy and implementing true relational sync would require extremely sophisticated solutions and even needing an atomic clock for full consistency across nodes (like google spanner). So, if your app truly needs SQL power on the client, local-first might complicate things.
In Local-First, most tools use NoSQL because it makes replication and conflict handling easy.
That's a long list of challenges! In summary, local-first approaches introduce distributed data issues on the client side that web developers usually didn't have to deal with. Despite these challenges, the local-first movement is steadily growing because the benefits to user experience and data control are very compelling and modern tools are emerging to mitigate a lot of these difficulties. All of these are solved or solvable for your specific use-case, just keep them in mind before you start architecting your local-first app.
Local-First vs. Traditional Online-First Approaches
So now that you know the pros and cons about Local-First. Lets directly compare it to your previous "online-first" stack:
Connectivity and Offline Usage
- Local-first: Apps like WhatsApp store messages locally on your device, letting you read past messages and even compose new ones without a stable network connection. Once online, the messages sync with the server and other participants.
- Online-first: Purely cloud-based apps typically stop functioning (beyond simple caching) when the network or server goes down. They rely on a constant connection to fetch or store user data.
Latency and Performance
- Local-first: Because data operations happen on the device, you see near-instant interactions (e.g., typing and reading chats feels very responsive, as the messages are on your phone). Syncing occurs in the background without delaying the user.
- Online-first: Most interactions involve a round-trip to the server, adding network latency and potentially requiring loading states or fallback UIs. If the network is slow or unreliable, users can experience delays when sending or receiving updates.
Complexity and Conflict Resolution
- Local-first: Much of the complexity like storing data or handling conflicts, shifts to the client. WhatsApp, for instance, caches all messages locally and queues unsent messages offline. Once reconnected, it must reconcile with the server and other devices, especially if the same account is used on multiple platforms.
- Online-first: A single central server manages data and concurrency, so clients remain thinner. However, the app becomes unusable if connectivity is lost, and any server downtime directly impacts all users.
Data Ownership and Storage Limits
- Local-first: Users hold a complete copy of data on their own device, retaining control and quick access. This can raise challenges when data sets are very large; phone storage might be insufficient, or backups may be harder to guarantee.
- Online-first: Storing all data in the cloud scales more easily, and providers often manage backups automatically. On the downside, users depend on the service and must trust it to protect their data.
When to Choose Which
- Local-first: Particularly helpful for scenarios where offline operation and immediate responsiveness matter, such as chat apps (like WhatsApp), field tools in low-connectivity environments, or any use case where users can't rely on being online 24/7.
- Online-first: Well-suited for systems that demand real-time central control or massive data aggregation with minimal offline needs, such as large-scale analytics platforms or services where guaranteed immediate global consistency is essential.
- Hybrid: In reality, most modern apps often blend these approaches, giving users partial offline capabilities (caching, queued updates) alongside a robust central service. This hybrid method offers the benefits of local speed and resilience, while still leveraging cloud infrastructure for collaboration and global reach. But a truth local-first app is way more than just a cache.
Offline-First vs. Local-First
In the early days of offline-capable web apps (around 2014), the common phrase was "Offline-First". Tools like PouchDB popularized the notion that developers should assume devices are often offline or have flaky connections, so apps must continue to work seamlessly without a network. The guiding principle was "apps should treat being online as optional." If a user has no internet access, the application's core features still function, saving or queuing data locally, and automatically synchronizing once connectivity is restored.

Over time, this focus on offline support evolved into the broader concept of "Local-First Software," (see Ink & Switch) emphasizing not just offline operation but also the technical underpinnings of storing data locally in the client application. While offline-first is primarily about resilience to network loss, local-first highlights ownership, privacy, and performance benefits of keeping the primary data on the user's device. Most tools these days extended the original offline-first concepts, adding real-time reactivity, custom sync, and more nuances like conflict resolution or encryption.

However, the term "local-first" can be confusing to non-technical audiences because many people (especially in the US) associate "local first" with community-oriented movements that encourage buying from nearby businesses or supporting local initiatives. To reduce ambiguity, it may be clearer to use "local first software" or "local first development" in your documentation and marketing materials. When creating branding or logos around local-first software, avoid using the "Google Maps Pin" as a symbol. This icon typically implies geolocation or physical locality further mixing up the notion of "location-based services" with "on-device data storage."
Do People Actually Use Local-First or Is It Just a Trend?
If we look at npm download statistics, we see that PouchDB - one of the oldest libraries for local-first apps - has about 53k downloads each week, and RxDB - a newer library - has about 22k weekly downloads. Other local-first tools often have even fewer downloads. In comparison, a popular library like react-query, which does not focus on local storage, is downloaded about 1.6 million times a week. These numbers show that local-first libraries, while used, are not as common as some of the more traditional tools.
One reason is that local-first is still a new idea. Many developers are used to traditional "online-first" approaches, so switching to a local database and then syncing changes later can feel unfamiliar. Developers must learn different patterns, deal with offline synchronization, and handle possible conflicts. That extra work can be a barrier to adoption which might change in the future as tooling improves.
While most of RxDB is open source, there are also premium plugins that help sustain RxDB as a long-term project. Because people purchase these plugins, we gains insights into how developers are using local-first features:
- About half of these users mainly want offline functionality for cases such as farming equipment, mining, construction, or even a shrimp farm app.
- The other half focus on faster, real-time UIs for to-do or reading apps, a space launch planning tool, and various dashboard apps. This range of use cases highlights both the resilience offline mode can offer and the performance boost that local databases can provide when synced in the background.
Why Local-First Is the Future
Early in the history of the web, users expected static pages. If you wanted to see new content, you reloaded the page. That was normal at the time, and nobody found it strange because everything worked that way.
Then, as more sites added real-time features - auto-updating feeds, live notifications, single-page apps - suddenly those older "reload-only" sites began to feel slow or outdated. Why wait for a manual refresh when real-time data was possible and readily available?
The same pattern is happening with local-first apps. Right now, most sites are still built around network availability. We see loading spinners whenever data is fetched, and we simply wait for the server response. As local-first experiences become commonplace - removing spinners, letting users keep working when offline, and syncing in the background - everything else will start to feel frustratingly behind. Users won't tolerate slow or blocked interactions if they've seen apps that respond instantly and remain usable offline. They'll expect that as the default and we'll likely see growing pressure on developers to eliminate those extra loading steps. For many users, the experience of immediate local writes will become not just a perk, but an expectation!
FAQ
What are the differences between an offline-first database and a cloud-first database for remote areas?
An offline-first database stores data locally on the user device. A cloud-first database stores data on a remote server. Field workers in remote areas often face poor network connectivity. An offline-first database allows users to read and write data without an internet connection. A cloud-first database requires continuous internet access to function. An offline-first approach synchronizes data automatically when a connection becomes available. A cloud-first approach blocks users from working during offline periods. You choose an offline-first database to ensure continuous productivity in remote locations.
What are the core advantages of local-first data storage?
Local-first data storage provides Zero Latency because data is read and written directly to the local device without waiting for network requests. It guarantees extreme Reliability since the application remains fully functional regardless of internet connectivity (offline support). Furthermore, it improves user Privacy by keeping sensitive data on the native client rather than a centralized server, and significantly reduces cloud infrastructure costs by offloading database compute to the user's hardware.
Why does local-first architecture matter for JavaScript applications?
JavaScript applications, particularly Single Page Applications (SPAs) built with React, Vue, or Angular, are heavily state-driven. A local-first architecture aligns perfectly with this paradigm by using client-side databases like RxDB to instantly manage the application state locally. This eliminates loading spinners, provides instant visual feedback, and bridges the gap between web applications and native desktop/mobile app performance.
What does offline-first and local-first mean for web apps?
Offline-First means designing an application to function properly without an internet connection, often caching resources and queueing actions to sync later. Local-First takes this further: it means the primary source of truth for the application is the local database on the device, rather than a remote cloud server. The cloud merely acts as an eventual syncing mechanism (or backup) in the background, rather than the primary endpoint for every user interaction.
Are applications like WorkFlowy or Capacities considered local-first?
Yes, applications like WorkFlowy, Capacities, Notion (to an extent), and Linear use local-first or heavily optimized offline-first architectures. They load the user's workspace into the local browser or desktop client memory/database immediately upon startup. Every interaction mutates the local state first to provide instant UI feedback, and then asynchronous replication protocols silently sync those changes to their backend servers in the background.
See also
![]()
- Discuss this topic on HackerNews
- Local-First Technologies: A list of databases and technologies (besides RxDB) that support offline-first or local-first use cases.
- Discord: Join our Discord server to talk with people and share ideas about this topic.
- Ink & Switch: The "original" paper about Local-First from 2019 where the naming of local-first Software was first used and described.
- Learn how to build a local-first Application with RxDB.