Local Vector Database with RxDB and transformers.js in JavaScript
The local-first revolution is here, changing the way we build apps! Imagine a world where your app's data lives right on the user's device, always available, even when there's no internet. That's the magic of local-first apps. Not only do they bring faster performance and limitless scalability, but they also empower users to work offline without missing a beat. And leading the charge in this space are local database solutions, like RxDB.
![]()
But here's where things get even more exciting: when building local-first apps, traditional databases often fall short. They're great at searching for exact matches, like numbers or strings, but what if you want to search by meaning, like sifting through emails to find a specific topic? Sure, you could use RegExp, but to truly unlock the power of semantic search and similarity-based queries, you need something more cutting-edge. Something that really understands the content of the data.
Enter vector databases, the game-changers for searching data by meaning! They have unlocked these new possibilities for storing and querying data, especially in tasks requiring semantic search and similarity-based queries. With the help of a machine learning model, data is transformed into a vector representation that can be stored, queried and compared in a database.
But unfortunately, most vector databases are designed for server-side use, typically running in large cloud clusters, not to run on a users device. To fix that, in this article, we will combine RxDB and transformers.js to create a local vector database running in the browser with JavaScript. It stores data in IndexedDB, and uses a machine learning model with WebAssembly locally, without the need for external servers.
-
transformers.js is a powerful framework that allows machine learning models to run directly within JavaScript using WebAssembly or WebGPU.
-
RxDB is a NoSQL, local-first database with a flexible storage layer that can run on any JavaScript runtime, including browsers and mobile environments. (You are reading this article on the RxDB docs).
A local vector database offers several key benefits:
- Zero network latency: Data is processed locally on the user's device, ensuring near-instant responses.
- Offline functionality: Data can be queried even without an internet connection.
- Enhanced privacy: Sensitive information remains on the device, never needing to leave for external processing.
- Simple setup: No backend servers are required, making deployment straightforward.
- Cost savings: By running everything locally, you avoid fees for API access or cloud services for large language models.
In this article only the important source code parts are shown. You can find the full open-source vector database implementation at the github repository.
What is a Vector Database?
A vector database is a specialized database optimized for storing and querying data in the form of high-dimensional vectors, often referred to as embeddings. These embeddings are numerical representations of data, such as text, images, or audio, created by machine learning models like MiniLM. Unlike traditional databases that work with exact matches on predefined fields, vector databases focus on semantic similarity, allowing you to query data based on meaning rather than exact values.
A vector, or embedding, is essentially an array of numbers, like
[0.56, 0.12, -0.34, -0.90].
For example, instead of asking "Which document has the word 'database'?", you can query "Which documents discuss similar topics to this one?" The vector database compares embeddings and returns results based on how similar the vectors are to each other.
Vector databases handle multiple types of data beyond text, including images, videos, and audio files, all transformed into embeddings for efficient querying. Mostly you would not train a model by yourself and instead use one of the public available transformer models.
Vector databases are highly effective in various types of applications:
- Similarity Search: Finds the closest matches to a query, even when the query doesn't contain the exact terms.
- Clustering: Groups similar items based on the proximity of their vector representations.
- Recommendations: Suggests items based on shared characteristics.
- Anomaly Detection: Identifies outliers that differ from the norm.
- Classification: Assigns categories to data based on its vector's nearest neighbors.
In this tutorial, we will build a vector database designed as a Similarity Search for text. For other use cases, the setup can be adapted accordingly. This flexibility is why RxDB doesn't provide a dedicated vector-database plugin, but rather offers utility functions to help you build your own vector search system.
Generating Embeddings Locally in a Browser
For the first step to build a local-first vector database we need to compute embeddings directly on the user's device. This is where transformers.js from huggingface comes in, allowing us to run machine learning models in the browser with WebAssembly. Below is an implementation of a getEmbeddingFromText() function, which takes a piece of text and transforms it into an embedding using the Xenova/all-MiniLM-L6-v2 model:
import { pipeline } from "@xenova/transformers";
const pipePromise = pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2');
async function getEmbeddingFromText(text) {
const pipe = await pipePromise;
const output = await pipe(text, {
pooling: "mean",
normalize: true,
});
return Array.from(output.data);
}This function creates an embedding by running the text through a pre-trained model and returning it in the form of an array of numbers, which can then be stored and further processed locally.
Vector embeddings from different machine learning models or versions are not compatible with each other. When you change your model, you have to recreate all embeddings for your data.
Storing the Embeddings in RxDB
To store the embeddings, first we have to create our RxDB Database with the localstorage storage that stores data in the browsers localstorage. For more advanced projects, you can use any other RxStorage.
import { createRxDatabase } from 'rxdb';
import { getRxStorageLocalstorage } from 'rxdb/plugins/storage-localstorage';
const db = await createRxDatabase({
name: 'mydatabase',
storage: getRxStorageLocalstorage()
});Then we add a items collection that stores our documents with the text field that stores the content.
await db.addCollections({
items: {
schema: {
version: 0,
primaryKey: 'id',
type: 'object',
properties: {
id: {
type: 'string',
maxLength: 20
},
text: {
type: 'string'
}
},
required: ['id', 'text']
}
}
});
const itemsCollection = db.items;In our example repo, we use the Wiki Embeddings dataset from supabase which was transformed and used to fill up the items collection with test data.
const imported = await itemsCollection.count().exec();
const response = await fetch('./files/items.json');
const items = await response.json();
const insertResult = await itemsCollection.bulkInsert(
items
);Also we need a vector collection that stores our embeddings.
RxDB, as a NoSQL database, allows for the storage of flexible data structures, such as embeddings, within documents. To achieve this, we need to define a schema that specifies how the embeddings will be stored alongside each document. The schema includes fields for an id and the embedding array itself.
await db.addCollections({
vector: {
schema: {
version: 0,
primaryKey: 'id',
type: 'object',
properties: {
id: {
type: 'string',
maxLength: 20
},
embedding: {
type: 'array',
items: {
type: 'string'
}
}
},
required: ['id', 'embedding']
}
}
});
const vectorCollection = db.vector;When storing documents in the database, we need to ensure that the embeddings for these documents are generated and stored automatically. This requires a handler that runs during every document write, calling the machine learning model to generate the embeddings and storing them in a separate vector collection.
Since our app runs in a browser, it's essential to avoid duplicate work when multiple browser tabs are open and ensure efficient use of resources. Furthermore, we want the app to resume processing documents from where it left off if it's closed or interrupted. To achieve this, RxDB provides a pipeline plugin, which allows us to set up a workflow that processes items and stores their embeddings. In our example, a pipeline takes batches of 10 documents, generates embeddings, and stores them in a separate vector collection.
const pipeline = await itemsCollection.addPipeline({
identifier: 'my-embeddings-pipeline',
destination: vectorCollection,
batchSize: 10,
handler: async (docs) => {
await Promise.all(docs.map(async(doc) => {
const embedding = await getVectorFromText(doc.text);
await vectorCollection.upsert({
id: doc.primary,
embedding
});
}));
}
});However, processing data locally presents performance challenges. Running the handler with a batch size of 10 takes around 2-4 seconds per batch, meaning processing 10k documents would take up to an hour. To improve performance, we can do parallel processing using WebWorkers. A WebWorker runs on a different JavaScript process and we can start and run many of them in parallel.
Our worker listens for messages and performance the embedding generation on each request. It then sends the result embedding back to the main thread.
// worker.js
import { getVectorFromText } from './vector.js';
onmessage = async (e) => {
const embedding = await getVectorFromText(e.data.text);
postMessage({
id: e.data.id,
embedding
});
};On the main thread we spawn one worker per core and send the tasks to the worker instead of processing them on the main thread.
// create one WebWorker per core
const workers = new Array(navigator.hardwareConcurrency)
.fill(0)
.map(() => new Worker(new URL("worker.js", import.meta.url)));let lastWorkerId = 0;
let lastId = 0;
export async function getVectorFromTextWithWorker(text: string): Promise<number[]> {
let worker = workers[lastWorkerId++];
if(!worker) {
lastWorkerId = 0;
worker = workers[lastWorkerId++];
}
const id = (lastId++) + '';
return new Promise<number[]>(res => {
const listener = (ev: any) => {
if (ev.data.id === id) {
res(ev.data.embedding);
worker.removeEventListener('message', listener);
}
};
worker.addEventListener('message', listener);
worker.postMessage({
id,
text
});
});
}
const pipeline = await itemsCollection.addPipeline({
identifier: 'my-embeddings-pipeline',
destination: vectorCollection,
batchSize: navigator.hardwareConcurrency, // one per CPU core
handler: async (docs) => {
await Promise.all(docs.map(async (doc, i) => {
const embedding = await getVectorFromTextWithWorker(doc.body);
/* ... */
});
}
});This setup allows us to utilize the full hardware capacity of the client's machine. By setting the batch size to match the number of logical processors available (using the navigator.hardwareConcurrency API) and running one worker per processor, we can reduce the processing time for 10k embeddings to about 5 minutes on my developer laptop with 32 CPU cores.
Comparing Vectors by calculating the distance
Now that we have stored our embeddings in the database, the next step is to compare these vectors to each other. Various methods are available to measure the similarity or difference between two vectors, such as Euclidean distance, Manhattan distance, Cosine similarity, and Jaccard similarity (and more). RxDB provides utility functions for each of these methods, making it easy to choose the most suitable method for your application. In this tutorial, we will use Euclidean distance to compare vectors. However, the ideal algorithm may vary depending on your data's distribution and the specific type of query you are performing. To find the optimal method for your app, it is up to you to try out all of these and compare the results.
Each method gets two vectors as input and returns a single number. Here's how to calculate the Euclidean distance between two embeddings with the vector utilities from RxDB:
import { euclideanDistance } from 'rxdb/plugins/vector';
const distance = euclideanDistance(embedding1, embedding2);
console.log(distance); // 25.20443With this we can sort multiple embeddings by how good they match our search query vector.
Searching the Vector database with a full table scan
To find out if our embeddings have been stored correctly and that our vector comparison works as should, let's run a basic query to ensure everything functions as expected. In this query, we aim to find documents similar to a given user input text. The process involves calculating the embedding from the input text, fetching all documents, calculating the distance between their embeddings and the query embedding, and then sorting them based on their similarity.
import { euclideanDistance } from 'rxdb/plugins/vector';
import { sortByObjectNumberProperty } from 'rxdb/plugins/core';
const userInput = 'new york people';
const queryVector = await getEmbeddingFromText(userInput);
const candidates = await vectorCollection.find().exec();
const withDistance = candidates.map(doc => ({
doc,
distance: euclideanDistance(queryVector, doc.embedding)
}));
const queryResult = withDistance
.sort(sortByObjectNumberProperty('distance'))
.reverse();
console.dir(queryResult);For distance-based comparisons, sorting should be in ascending order (smallest first), while for similarity-based algorithms, the sorting should be in descending order (largest first).
If we inspect the results, we can see that the documents returned are ordered by relevance, with the most similar document at the top:
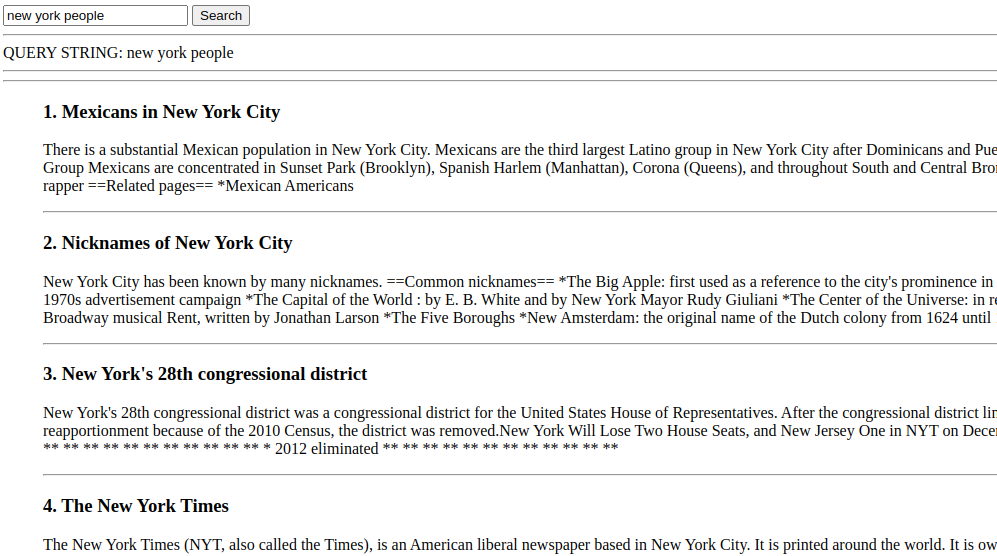
This demo page can be run online here.
However our full-scan method presents a significant challenge: it does not scale well. As the number of stored documents increases, the time taken to fetch and compare embeddings grows proportionally. For example, retrieving embeddings from our test dataset of 10k documents takes around 700 milliseconds. If we scale up to 100k documents, this delay would rise to approximately 7 seconds, making the search process inefficient for larger datasets.
Indexing the Embeddings for Better Performance
To address the scalability issue, we need to store embeddings in a way that allows us to avoid fetching all of them from storage during a query. In traditional databases, you can sort documents by an index field, allowing efficient queries that retrieve only the necessary documents. An index organizes data in a structured, sortable manner, much like a phone book. However, with vector embeddings we are not dealing with simple, single values. Instead, we have large lists of numbers, which makes indexing more complex because we have more than one dimension.
Vector Indexing Methods
Various methods exist for indexing these vectors to improve query efficiency and performance:
- Locality Sensitive Hashing (LSH): LSH hashes data so that similar items are likely to fall into the same bucket, optimizing approximate nearest neighbor searches in high-dimensional spaces by reducing the number of comparisons.
- Hierarchical Small World: HSW is a graph structure designed for efficient navigation, allowing quick jumps across the graph while maintaining short paths between nodes, forming the basis for HNSW's optimization.
- Hierarchical Navigable Small Worlds (HNSW): HNSW builds a hierarchical graph for fast approximate nearest neighbor search. It uses multiple layers where higher layers represent fewer, more connected nodes, improving search efficiency in large datasets.
- Distance to samples: While testing different indexing strategies, I found out that using the distance to a sample set of items is a good way to index embeddings. You pick like 5 random items of your data and get the embeddings for them out of the model. These are your 5 index vectors. For each embedding stored in the vector database, we calculate the distance to our 5 index vectors and store that
numberas an index value. This seems to work good because similar things have similar distances to other things. For example the words "shoe" and "socks" have a similar distance to "boat" and therefore should have roughly the same index value.
When building local-first applications, performance is often a challenge, especially in JavaScript. With IndexedDB, certain operations, like many sequential get by id calls, are slow, while bulk operations, such as get by index range, are fast. Therefore, it's essential to use an indexing method that allows embeddings to be stored in a sortable way, like Locality Sensitive Hashing or Distance to Samples. In this article, we'll use Distance to Samples, because for me it provides the best default behavior for the sample dataset.
Storing indexed embeddings in RxDB
The optimal way to store index values alongside embeddings in RxDB is to place them within the same RxCollection. To ensure that the index values are both sortable and precise, we convert them into strings with a fixed length of 10 characters. This standardization helps in managing values with many decimals and ensures proper sorting in the database.
Here's is our schema example schema where each document contains an embedding and corresponding index fields:
const indexSchema = {
type: 'string',
maxLength: 10
};
const schema = {
"version": 0,
"primaryKey": "id",
"type": "object",
"properties": {
"id": {
"type": "string",
"maxLength": 100
},
"embedding": {
"type": "array",
"items": {
"type": "number"
}
},
// index fields
"idx0": indexSchema,
"idx1": indexSchema,
"idx2": indexSchema,
"idx3": indexSchema,
"idx4": indexSchema
},
"required": [
"id",
"embedding",
"idx0",
"idx1",
"idx2",
"idx3",
"idx4"
],
"indexes": [
"idx0",
"idx1",
"idx2",
"idx3",
"idx4"
]
}To populate these index fields, we modify the RxPipeline handler accordingly to the Distance to samples method. We calculate the distance between the document's embedding and our set of 5 index vectors. The calculated distances are converted to string and stored in the appropriate index fields:
import { euclideanDistance } from 'rxdb/plugins/vector';
const sampleVectors: number[][] = [/* the index vectors */];
const pipeline = await itemsCollection.addPipeline({
handler: async (docs) => {
await Promise.all(docs.map(async(doc) => {
const embedding = await getEmbedding(doc.text);
const docData = { id: doc.primary, embedding };
// calculate distance to all samples
// and store them in the index fields
new Array(5).fill(0).map((_, idx) => {
const indexValue = euclideanDistance(sampleVectors[idx], embedding);
docData['idx' + idx] = indexNrToString(indexValue);
});
await vectorCollection.upsert(docData);
}));
}
});Searching the Vector database with utilization of the indexes
Once our embeddings are stored in an indexed format, we can perform searches much more efficiently than through a full table scan. While this indexing method boosts performance, it comes with a tradeoff: a slight loss in precision, meaning that the result set may not always be the optimal one. However, this is generally acceptable for similarity search use cases.
There are multiple ways to leverage indexes for faster queries. Here are two effective methods:
- Query for Index Similarity in Both Directions: For each index vector, calculate the distance to the search embedding and fetch all relevant embeddings in both directions (sorted before and after) from that value.
async function vectorSearchIndexSimilarity(searchEmbedding: number[]) {
const docsPerIndexSide = 100;
const candidates = new Set<RxDocument>();
await Promise.all(
new Array(5).fill(0).map(async (_, i) => {
const distanceToIndex = euclideanDistance(
sampleVectors[i], searchEmbedding
);
const [docsBefore, docsAfter] = await Promise.all([
vectorCollection.find({
selector: {
['idx' + i]: {
$lt: indexNrToString(distanceToIndex)
}
},
sort: [{ ['idx' + i]: 'desc' }],
limit: docsPerIndexSide
}).exec(),
vectorCollection.find({
selector: {
['idx' + i]: {
$gt: indexNrToString(distanceToIndex)
}
},
sort: [{ ['idx' + i]: 'asc' }],
limit: docsPerIndexSide
}).exec()
]);
docsBefore.map(d => candidates.add(d));
docsAfter.map(d => candidates.add(d));
})
);
const docsWithDistance = Array.from(candidates).map(doc => {
const distance = euclideanDistance((doc as any).embedding, searchEmbedding);
return {
distance,
doc
};
});
const sorted = docsWithDistance
.sort(sortByObjectNumberProperty('distance'))
.reverse();
return {
result: sorted.slice(0, 10),
docReads
};
}- Query for an Index Range with a Defined Distance: Set an
indexDistanceand retrieve all embeddings within a specified range from the index vector to the search embedding.
async function vectorSearchIndexRange(searchEmbedding: number[]) {
await pipeline.awaitIdle();
const indexDistance = 0.003;
const candidates = new Set<RxDocument>();
let docReads = 0;
await Promise.all(
new Array(5).fill(0).map(async (_, i) => {
const distanceToIndex = euclideanDistance(
sampleVectors[i], searchEmbedding
);
const range = distanceToIndex * indexDistance;
const docs = await vectorCollection.find({
selector: {
['idx' + i]: {
$gt: indexNrToString(distanceToIndex - range),
$lt: indexNrToString(distanceToIndex + range)
}
},
sort: [{ ['idx' + i]: 'asc' }],
}).exec();
docs.map(d => candidates.add(d));
docReads = docReads + docs.length;
})
);
const docsWithDistance = Array.from(candidates).map(doc => {
const distance = euclideanDistance((doc as any).embedding, searchEmbedding);
return {
distance,
doc
};
});
const sorted = docsWithDistance
.sort(sortByObjectNumberProperty('distance'))
.reverse();
return {
result: sorted.slice(0, 10),
docReads
};
};Both methods allow you to limit the number of embeddings fetched from storage while still ensuring a reasonably precise search result. However, they differ in how many embeddings are read and how precise the results are, with trade-offs between performance and accuracy. The first method has a known embedding read amount of docsPerIndexSide * 2 * [amount of indexes]. The second method reads out an unknown amount of embeddings, depending on the sparsity of the dataset and the value of indexDistance.
And that's it for the implementation. We now have a local first vector database that is able to store and query vector data.
Performance benchmarks
In server-side databases, performance can be improved by scaling hardware or adding more servers. However, local-first apps face the unique challenge that the hardware is determined by the end user, making performance unpredictable. Some users may have high-end gaming PCs, while others might be using outdated smartphones in power-saving mode. Therefore, when building a local-first app that processes more than a few documents, performance becomes a critical factor and should be thoroughly tested upfront.
Let's run performance benchmarks on my high-end gaming PC to give you a sense of how long different operations take and what's achievable.
Performance of the Query Methods
| Query Method | Time in milliseconds | Docs read from storage |
|---|---|---|
| Full Scan | 765 | 10000 |
| Index Similarity | 1647 | 934 |
| Index Range | 88 | 2187 |
As shown, the index similarity query method takes significantly longer compared to others. This is due to the need for descending sort orders in some queries sort: [{ ['idx' + i]: 'desc' }]. While RxDB supports descending sorts, performance suffers because IndexedDB does not efficiently handle reverse indexed bulk operations. As a result, the index range method performs much better for this use case and should be used instead. With its query time of only 88 milliseconds it is fast enough for all most things and likely such fast that you do not even need to show a loading spinner. Also it is faster compared to fetching the query result from a server-side vector database over the internet.
Performance of the Models
Let's also look at the time taken to calculate a single embedding across various models from the huggingface transformers list:
| Model Name | Time per Embedding in (ms) | Vector Size | Model Size (MB) |
|---|---|---|---|
| Xenova/all-MiniLM-L6-v2 | 173 | 384 | 23 |
| Supabase/gte-small | 341 | 384 | 34 |
| Xenova/paraphrase-multilingual-mpnet-base-v2 | 1000 | 768 | 279 |
| jinaai/jina-embeddings-v2-base-de | 1291 | 768 | 162 |
| jinaai/jina-embeddings-v2-base-zh | 1437 | 768 | 162 |
| jinaai/jina-embeddings-v2-base-code | 1769 | 768 | 162 |
| mixedbread-ai/mxbai-embed-large-v1 | 3359 | 1024 | 337 |
| WhereIsAI/UAE-Large-V1 | 3499 | 1024 | 337 |
| Xenova/multilingual-e5-large | 4215 | 1024 | 562 |
From these benchmarks, it's evident that models with larger vector outputs take longer to process. Additionally, the model size significantly affects performance, with larger models requiring more time to compute embeddings. This trade-off between model complexity and performance must be considered when choosing the right model for your use case.
Potential Performance Optimizations
There are multiple other techniques to improve the performance of your local vector database:
-
Shorten embeddings: The storing and retrieval of embeddings can be improved by "shortening" the embedding. To do that, you just strip away numbers from your vector. For example
[0.56, 0.12, -0.34, 0.78, -0.90]becomes[0.56, 0.12]. That's it, you now have a smaller embedding that is faster to read out of the storage and calculating distances is faster because it has to process less numbers. The downside is that you loose precision in your search results. Sometimes shortening the embeddings makes more sense as a pre-query step where you first compare the shortened vectors and later fetch the "real" vectors for the 10 most matching documents to improve their sort order. -
Optimize the variables in our Setup: In this examples we picked our variables in a non-optimal way. You can get huge performance improvements by setting different values:
- We picked 5 indexes for the embeddings. Using less indexes improves your query performance with the cost of less good results.
- For queries that search by fetching a specific embedding distance we used the
indexDistancevalue of0.003. Using a lower value means we read less document from the storage. This is faster but reduces the precision of the results which means we will get a less optimal result compared to a full table scan. - For queries that search by fetching a given amount of documents per index side, we set the value
docsPerIndexSideto100. Increasing this value means you fetch more data from the storage but also get a better precision in the search results. Decreasing it can improve query performance with worse precision.
-
Use faster models: There are many ways to improve performance of machine learning models. If your embedding calculation is too slow, try other models. Smaller mostly means faster. The model
Xenova/all-MiniLM-L6-v2which is used in this tutorial is about 1 year old. There exist better, more modern models to use. Huggingface makes these convenient to use. You only have to switch out the model name with any other model from that site. -
Narrow down the search space: By utilizing other "normal" filter operators to your query, you can narrow down the search space and optimize performance. For example in an email search you could additionally use a operator that limits the results to all emails that are not older than one year.
-
Dimensionality Reduction with an autoencoder: An autoencoder encodes vector data with minimal loss which can improve the performance by having to store and compare less numbers in an embedding.
-
Different RxDB Plugins: RxDB has different storages and plugins that can improve the performance like the IndexedDB RxStorage, the OPFS RxStorage, the sharding plugin and the Worker and SharedWorker storages.
![]()
Migrating Data on Model/Index Changes
When you change the index parameter or even update the whole model which was used to create the embeddings, you have to migrate the data that is already stored on your users devices. RxDB offers the Schema Migration Plugin for that.
When the app is reloaded and the updated source code is started, RxDB detects changes in your schema version and runs the migration strategy accordingly. So to update the stored data, increase the schema version and define a handler:
const schemaV1 = {
"version": 1, // <- increase schema version by 1
"primaryKey": "id",
"properties": {
/* ... */
},
/* ... */
};In the migration handler we recreate the new embeddings and index values.
await myDatabase.addCollections({
vectors: {
schema: schemaV1,
migrationStrategies: {
1: function(docData){
const embedding = await getEmbedding(docData.body);
new Array(5).fill(0).map((_, idx) => {
docData['idx' + idx] = euclideanDistance(mySampleVectors[idx], embedding);
});
return docData;
},
}
}
});Possible Future Improvements to Local-First Vector Databases
For now our vector database works and we are good to go. However there are some things to consider for the future:
- WebGPU is not fully supported yet. When this changes, creating embeddings in the browser have the potential to become faster. You can check if your current chrome supports WebGPU by opening
chrome://gpu/. Notice that WebGPU has been reported to sometimes be even slower compared to WASM but likely it will be faster in the long term. - Cross-Modal AI Models: While progress is being made, AI models that can understand and integrate multiple modalities are still in development. For example you could query for an image together with a text prompt to get a more detailed output.
- Multi-Step queries: In this article we only talked about having a single query as input and an ordered list of outputs. But there is big potential in chaining models or queries together where you take the results of one query and input them into a different model with different embeddings or outputs.
Follow Up
- Shared/Like my announcement tweet
- Read the source code that belongs to this article at github
- Learn how to use RxDB with the RxDB Quickstart
- Check out the RxDB github repo and leave a star ⭐